

なぜデータ利活用がうまくいかないのか?
「とりあえず貯めてきたデータ」を持て余してはいないでしょうか。ビックデータの利用やAIの活用が取りざたされてから久しく、多くの企業で膨大なデータを集積・保持するようになりました。一方で、そのデータを効果的に活用できている企業はまだまだ多くはありません。
その一つの理由として、データサイエンティストの不足が挙げられるでしょう。しかしながら、人材不足だけが原因というわけではありません。正しくデータと向き合うことができれば、効率的にデータを活用していく事が可能になります。本稿では、データ利活用に対する基本的なアプローチの方法や考え方をご紹介します。
データ分析の進め方
さて、CRISP-DM (Cross-Industry Standard Process for Data Mining) というものをご存じでしょうか。CRISP-DMは、一般的なデータ活用のプロセスを示したものであり、ビジネスの理解、データの理解、データの準備、モデル生成、評価、展開の5段階で構成されています。分析に携わる人であれば、CRISP-DMという言葉自体を聞いたことが無くとも、概ね同じような考え方で業務にあたっているでしょう。
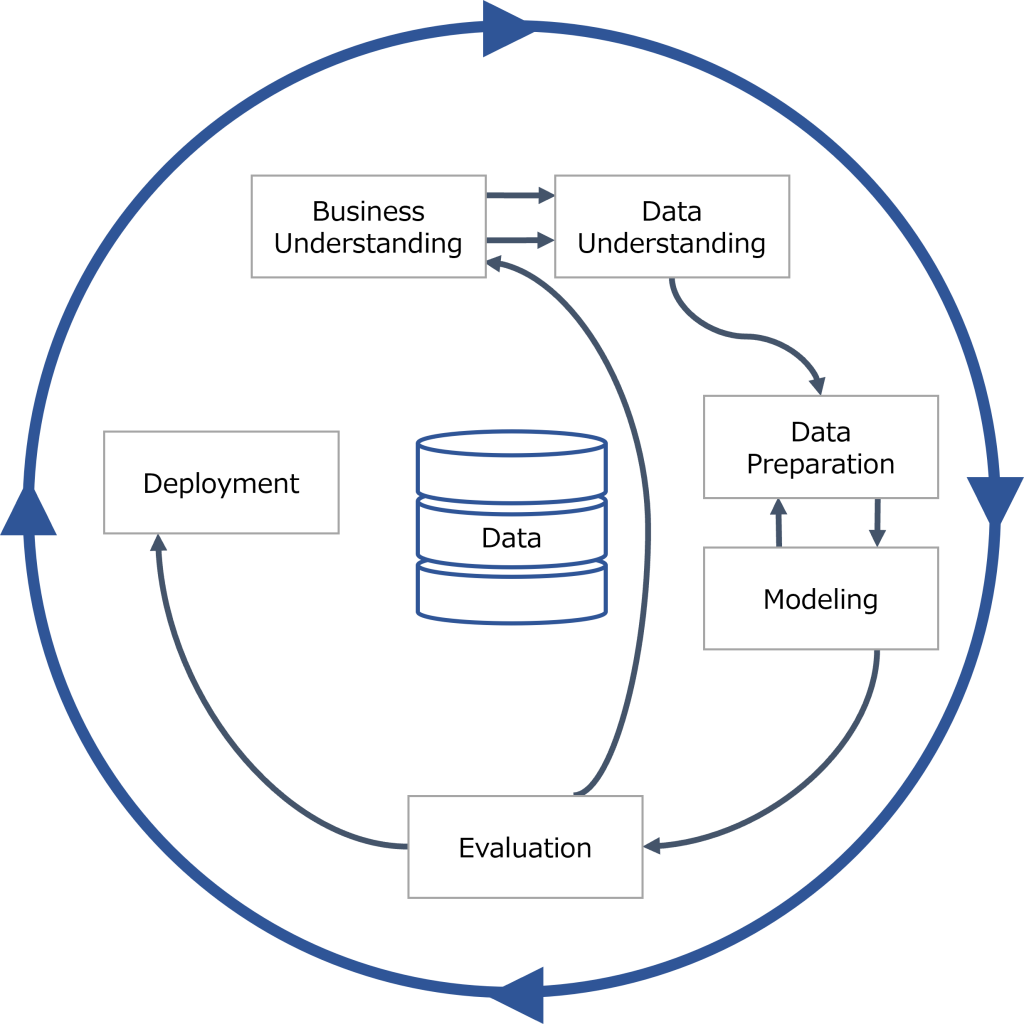
Process diagram showing the relationship between the different phases of CRISP-DM(J Data Warehousing (2000)より再描画)
ここでは、実際の現場で起こりがちな失敗要因などを交えながら、それぞれのステップのアプローチの仕方やポイントを見ていきます。
Business Understanding(ビジネスの理解)
データ活用の最初のステップは、目的を明確にして仮説をたてることです。経営や業務における課題に基づいて、目的を達成するための仮設をたてる事が、プロセス全体の中で最も重要になります。逆に言うと「集めたデータをとりあえず分析して、わかったことをもとに施策を立てる」というようなアプローチでは、効果的な施策をたてる事は困難になります。
目的が不明瞭なまま手元にあるデータを描画し簡単な分析を行ったとしても、現状を把握する以上の結果を得ることは難しいでしょう。仮説が無ければ、データのなかで注目すべきポイントが不明瞭になり、価値のある特徴を見出す事は困難です。また、仮説に基づいたデータの収集を行わない場合、意思決定を行うために必要なデータが十分に揃っていることは稀です。データから経営判断や業務改善につながる示唆を得るためには、仮説検証が最も重要なプロセスになります。
Data Understanding(データの理解)
次のステップでは、分析対象となるデータを理解し、必要なデータを見極めます。分析対象のデータの特性やそれぞれのデータ群の関係性等に基づき、目的が達成可能かどうかを検討します。この時、新たに必要なデータの洗い出しを行います。
このステップでは、データの取得条件や制約等の情報だけでなく、データを可視化することで概要の理解も行います。ある時刻の状態や時系列での変化、データの分布(ヒストグラムを利用した確認等がよく行われる)等を目的に合わせて簡単に描画またはグラフ化し、データの概観を確認します。また、欠損値や外れ値等の量などデータの状態についても簡単に把握しておきます。
データの理解の過程で、ビジネス上の課題の理解が深まり新たな課題が見つかったり、当初考えていた課題ではない部分に課題がある事等が明らかになることがあります。このため、「ビジネス理解」と「データの理解」のステップとを行き来しながら、最初のステップで立てた仮説を精緻化させます。
Data Preparation (データの準備)
さて、データの理解を深めたところで、やっと統計的な分析手法やAIなどを用いた分析に移る事ができるようになります。このステップでは、分析手法を実施するために必要な準備を行います。
実務で収集されたデータは、そのまま利用できない場合がほとんどです。例えば、数値的に処理できないデータは、解析可能な形に変換する必要があります。また、データ収集の際に人の手によるオペレーションが入る場合、ミスが生じる事は防ぐことができません。さらに、データを取得するためのセンサーの不具合や通信環境の影響、システム障害等よるエラーデータの混入および欠損なども避ける事は困難です。また、異常値や欠損値だけでなく、データ自体は正常に取得されている外れ値をどのように扱うかも重要な検討課題です。
データの準備のステップでは、上記のようなそのままでは利用できないデータの補正や変換を行います。
Modeling(モデリング)
データが準備できたところで、はじめて、統計的あるいはAIを用いた分析手法を実施します。このとき、最初のステップで検討した仮説が検証可能な分析手法を検討します。
流行っているからという理由で画像解析を実施し闇雲にクラスター分析を行ったり、データの特性を無視した相関分析を行ったりしては、分析の目的が達成されません。それどころか、間違ったデータの解釈を行い、その後の業務や事業に悪影響を与えることすらあります。ビジネスとデータの理解に基づいて、適切な分析手法を検討する必要があります。
また、結果を確認することで新たな分析手法をとる必要が出てくることが往々にしてあります。さらに、データの準備を行ってもノイズの除去が不十分であり解釈が難しいままであることも多く、データの準備とモデリングは繰り返し行う必要があります。
Evaluation(評価)
モデリングができれば、今度はモデルの評価を行います。モデルの精度に問題がないかなどの観点で分析結果を評価します。さらに、このステップは初めに立てた仮説の検証のステップでもあります。仮説が正しくなかった場合は、最初のステップに立ち戻り新たに仮説の構築を行います。
このような仮説検証のステップを繰り返すことで、ようやくビジネスに何らかの形で寄与することのできる分析となります。
Deployment(展開)
最後のステップでは、一連のデータ分析の結果を施策に展開します。分析はやりっぱなしでは意味がありません。時間とお金をかけて分析を行ったのは、「分析を行った」というポーズをとるためではなかったはずです。最初のステップで確認した目的を達成するためには、分析の結果を施策に繋げる必要があります。
データ活用を推進する
”ビックデータが話題なので、データを集めた。しかし、データの収集にも保持にも維持費がかかっており何とか活用しなければならない。”
一度はこのような状況に直面しているのではないでしょうか。このような「データを活用しなければならない状況」は効果的なデータ活用プロセスを阻害しがちです。
もちろん、活用方法が見えないまま闇雲に集めたデータも、有効に活用されている例もあるでしょう。しかしながら、これは容易ではないはずです。例えば、不要なデータをため込んでおけるだけの資本力をもち、ビジネスに対する深い造詣と高度な専門知識を両立するデータサイエンティストを参画させることはできるでしょうか。一般的には、このような力業での解決は現実的ではないでしょう。
データ活用を推進するために重要な3つの要素
先述の通り、データを活用する上で重要なことは、「目的を明確にし仮説検証を行ったうえで施策に展開する」という一連の流れを実直に行う事です。さて、それではこのような分析プロセスを実行するためには、どのような事に気を付ければよいのでしょうか。
1. ビジネスの理解と分析目的の明確化
まず1つ目は、繰り返しになりますが、ビジネスの理解と分析目的の明確化です。仮説検証を繰り返し、施策に繋げなければ、すべてのプロセスは意味のないものになってしまいます。
2. 推進体制の構築
次にあげられるのは、推進体制の構築でしょう。「ビジネス課題の深い理解」「データ分析に対する専門知識」「データエンジニアリングに対する専門知識」の3つスキルが重要になってきます。
例えば、仮説を立てるためにはビジネス面と分析面の両方の視点が必要であり、データの収集の過程では必要データの検討は分析面のスキルを要し、実装に向けた検討は技術的な要素が大きくなります。データ分析プロセスを推進してくためには、これらの専門スキルの協力体制が非常に重要な要素となります。
3. 部署内および部署横断的な協力体制の構築
さらに、部署内および部署横断的な協力体制の構築も非常に重要な要素になってきます。時には、社内全体のデータ活用に対する前向きな雰囲気を醸成する事も重要な要素になるでしょう。
施策を実行するためには、意思決定者や実務担当者との適切なコミュニケーションにより、データ活用プロセスに主体的に参加させるように働きかける必要が出てきます。また、データの取り扱いに関しても部署間の連携は非常に重要な要素になります。
例えば、個人消費者向け小売業におけるデジタルマーケティング施策で、販促ではどのようなコンテンツを提供するべきかという課題を考えてみます。このようなケースでは、どのような商品が購買されたかだけでなく、商品を購入した人がアプリや店舗でどのような行動をとっているか、どのようなサービスを受けた時に購買につながるかなどが分析対象となるでしょう。しかしながら、それぞれのデータやシステムを管理運用している部門は異なっている場合も多いでしょう。
それぞれの業務部門が個別にシステム構築を主導した場合やそれぞれのシステムが個別最適化されているような場合では、顧客に紐付いたデータとして部門間を横断して扱うことは困難になる傾向にあります。さらに、これらを一元的に扱えるように改修することで、運営負荷が高まることもしばしばあります。
このような部署間での調整を要するようなケースでは、分析担当者の権限では解決できないことも多いでしょう。また、組織の文化的な側面として、部署を横断した協力体制の構築が困難になるケースがあることは容易に想像できます。会社全体でデータ活用に対するリテラシーを高め、データを積極的に活用したいと考えられる雰囲気を醸成することが重要になるのです。
データを集めるということ
さて、闇雲にデータを集めても意味がない。ということを繰り返し述べてきました。ではどのようにデータを集めればよいでしょうか。収集すべきデータは分析目的や仮説に依存するため、一概に特定することはできません。しかしながら、収集したデータが使えないケースを考えると、概ね「目的のないデータ収集」「技術的な課題によるデータの不備」の二つに分類できると考えられます。社内のデータが活用できない要因を例に、これら2つのケースを考えてみます。
目的のないデータ収集
目的のないデータ収集が要因で起こるものとして、以下のような問題があります。
- 分析に必要になるデータがない
- 情報が更新されていない
分析に必要なデータが存在しないことは、非常に多くのプロジェクトが抱えている課題です。データの整備を行う段階で活用方法が明確ではない場合、収集すべきデータや管理方法を厳密に規定することができません。ビジネス課題を検討する段階でデータサイエンスの知見があるメンバーを参画させ、集めるべきデータを明確にしてプロジェクトを進めることが重要となります。
データ分析の段階で分析に必要なデータが収集できていないことが分かった場合には、代替データの利用や外部データ活の活用も視野に入れた検討がなされるでしょう。特に代替データを利用した場合は、データの精度に問題が出てくる可能性もあるため、注意が必要になります。
また、利用されていないデータについては、メンテナンスが滞っていたとしても発見が遅れ、気づいた時には使えなくなっているということも起こりえます。分析したいデータが更新されなくなっている場合は、運用方法を改めて検討する必要があるでしょう。
技術的な課題によるデータの不備
技術的な課題によるデータの不備が要因で起こるものとして、以下のような問題があります。
- 取得元が異なるデータを関連付けられない
- データの精度にばらつきがある
- データ形式が複雑で解析に専門技術を要する
これらは、取得対象のデータの特性や技術的な制約に起因するケースが多いのではないでしょうか。取得元の異なるデータを一元的に管理する方法として、名寄せ等の紐付けの工夫を行う方法の他、複数のサービスを一つの基盤で賄う方法などさまざまな技術的アプローチがとられています。このような技術的な課題は日々改善されており、最新情報のキャッチアップを続けることで、利用可能になるデータを増やしていくことできると考えられます。
また、データ取得を行うシステムの構築時に、データサイエンスやデータエンジニアリングの高度な専門知識を持つメンバーを参画させることで、技術的な制約を抑えた効率的なデータ基盤を構築することが可能になるでしょう。
ビックデータ、スモールデータ、AI、データドリブンなどさまざまなバズワードが溢れ、データ活用の重要性は広く認知されています。一方で、「データ活用を行うこと」そのものを意識するあまり、ビジネス上の課題の見極めが疎かになっているケースも散見されます。苦労して収集し維持してきたデータを何とか活用したいというニーズは非常に重要です。しかしながら、ビジネス貢献を考える上では、課題をどのように解決していくのかという視点を忘れてはなりません。
保持しているデータだけで課題が解決できないのであれば、必要なデータを新たに付加することなどを検討する必要があるでしょう。データ解析から思うような結果が得られない場合は、仮説やモデルの見直しを繰り返す必要があります。あくまで目的達成を念頭に置いて、柔軟に対応していくことが重要です。
「ビジネス」「データサイエンス」「データエンジニアリング」の3点から深く検討し、仮設検証を繰り返すことで、はじめて適切な施策が実施できるようになります。データ活用の文脈では、いわゆる目的と手段が逆転した状態になりがちですが、適切にデータを活用するためにもCRISP-DMのプロセスを適用した分析プロセスを意識することが重要になってきます。
引用・参考
- Shearer C., The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000)
- データ利活用のポイント集 (経済産業省):https://www.meti.go.jp/policy/economy/chizai/chiteki/pdf/datapoint.pdf
記事を書いた人
舘野 愛実